期刊封面

腾讯天衍实验室郑冶枫:医学影像AI为什么需要小样本学习和域自适应技术?(2)
但影像诊断有很多独特的问题:
第一个挑战,数据量少。数据整个AI研发过程中最大的难题,其他领域通过爬虫、众包的方式可以获取大量已经标注的数据。这在医疗领域就非常困难,首先像核磁、CT等特定部位数据量和来源非常少,而且这些数据中往往还存在大量噪音。此外数据标注过程也比较困难,医疗数据的标注往往需要十年以上行业经验的医生才能完成。
第二个挑战,算法跨中心泛化能力差。AI产品在研发中,通常都是和一家科研能力强的医院做深度捆绑,利用医院里面所有数据进行交叉验证,在这家医院可能得到比较好的结果,甚至达到95%的准确率。
但这家医院研究出来的算法,一旦泛化到其他医院,就会出现模型准确度急剧下降,如果把两家医院的数据做比对就可以发现相差非常大,里面可能是因为设备的差异,不同设备使用不同的扫描参数,甚至疾病也存在差异,有些医院重症病人较多,有些医院轻症病人较多。
第三个挑战,准确度要求高。医疗是一个严谨的场景,所有诊断建议可能会对病人健康产生直接的影响。
我今天会分享前面两个问题的解决途径,第一个就是采用小样学习技术解决缺乏训练样本问题;第二个是采用域自适应的方法提高算法的泛化能力。
Med3D——构造3D医学影像的ImageNet
首先分享几个我们最近做的工作,第一个是Med3D:构造3D医学影像的ImageNet。
目前,小样本学习比较成熟的技术就是迁移学习。迁移学习就是将某个任务上训练好的模型迁移到另一个任务,小样本迁移学习则是源域已经有大量训练样本,而目标域只有少量样本的情况。

以这个图像为例,假设要开发一个老虎识别图像算法,但因为老虎是珍稀动物,我们接触老虎的概率很低,所以训练集里面就缺少老虎不同角度的图片。
但跟老虎很像的一个动物是橘猫,橘猫在各个场景下都可以得到海量的图片,所以就可以在橘猫的训练集上进行训练,之后通过微调就可以满足识别老虎,这就是典型的迁移学习案例。

迁移学习在医学影像上也有很好的应用场景,例如CT、MR等影像都是三维图像,而lmageNet预训练的模型都是二维图像,根本无法识别三维图像。
而如果把三维图形都转化为二维图像识别,就会丢失很多信息,这在医疗是不允许的。所以只能通过某种方法构造或预训练另一种直接识别三维图像的模型。
但实际二维影像数据也不多,我们只能聚少成多,一点点把二维影像数据积累起来,把小样本聚集起来成为大样本。
在这个过程中,医疗影像领域就有一个特别好的助推,就是每年大量的竞赛,每次竞赛都会公开数据集。数据集里面还都是经过医生投票,得到金标准的数据,甚至有的网站集合了所有公开竞赛的数据,现在就有200多个竞赛数据集,还在一直增长。
因为实验室更关注三维图像的处理,所以会把这些数据集里所有三维图像数据拿出来进行分割、标注、分类。
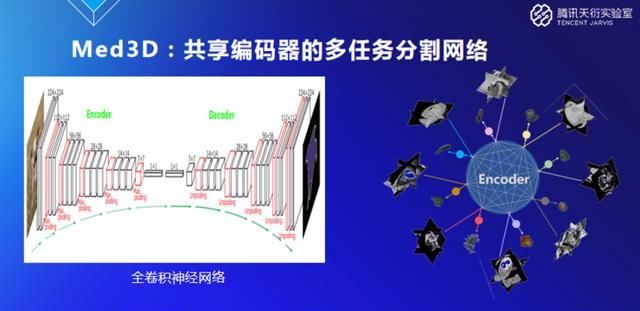

对于分割,现在最好的方法就是全卷积神经网络,主要包括两部分,一个是编码器,即图像做卷积下载压缩到一个低维空间,然后套一个解码器,做卷积上采样恢复成原来的分辨率,输出分割结果,这是现在几乎所有人都在用的一个分割技术。
我们数据的来源非常不一样,有CT、有核磁共振,而且分割的器官也不一样,解码器无法共享,但编码器是可以共享的,可以把编码器拿出来在其他任务上进行学习,跟随机初始化比起来有很大的提升。
做完这个以后,我们觉得这是一个非常基础的工作,很多医疗影像研究人员都可以从中受益,所以我们决定开源,当然前期肯定经过了腾讯的评估,这是腾讯在医疗AI领域的首次开源输出。
介绍小样本学习案例2:基于魔方变换的自监督学习刚才介绍的是我们做的第一个小样本学习的工作,毕竟这个工作还是需要做分割标注,这个工作量很大,于是我们接下来进行了自监督学习,只需要拿原始图像进来,通过构建自监督学习任务,这样就可以拿到这个任务本身需要的标注,通过图像本身训练,不需要额外的人工标注。
文章来源:《航空航天医学杂志》 网址: http://www.hkhtyxzz.cn/zonghexinwen/2020/0819/447.html
上一篇:北京朝阳医院童朝晖:半年“追疫”一万五千公里
下一篇:[文献]硫酸乙酰肝素蛋白聚糖在胶质母细胞瘤肿瘤微环境中的作用研究进展 |纪